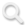一、问题的提出
2023年11月1日,首届全球人工智能(AI)安全峰会召开,随后发布的由中国等28国签署的《布莱切利宣言》指出,人工智能是机遇与风险并存的,各国应通力合作,使其在安全的前提下健康发展。CNNIC的报告指出,新一代的人工智能产业应用的驱动特征愈发明显,昭示着我国对人工智能技术、产品、服务等都有强烈的需求。随着人工智能(AI)与大数据等技术的发展与融合,出现了以Chat-GPT等为代表的更为智能的生成式人工智能(AIGC)。生成式人工智能所输出的人工智能生成物的性质及保护问题,引发了著作权法学界的争论。有学者从人工智能生成过程出发,主张生成物不属于著作权法意义上的作品。也有学者从人工智能生成结果出发,主张生成物具有可版权性。当前,后一类观点占了多数,前者可被称为过程论,后者则为结果论。
我国三例与人工智能生成物有关的著作权纠纷也存在过程论与结果论的倾向,分别从人工智能生成过程与生成行为,以及人工智能生成结果等角度来确定生成物的可版权性。在菲某诉网某案中,法院肯定了由威某先行库生成的报告具有独创性,但由于威某先行库(人工智能程序)不具有著作权法上的主体资格,故,其行为不能被认定为创作,涉案分析报告不属于作品。在腾某诉盈某案中,法院认为,涉案文章(人工智能生成物)的外表符合文字作品的形式要求,内容反映出了对数据信息的辨别、筛选,文章的结构合理、表达逻辑清晰,是由使用团队成员特意筛选、采用的结果。故,案涉文章具有独创性、构成作品,应予以保护。而在我国人工智能生成图画第一案中,法院则认可了使用者利用人工智能输出图画的行为属于创作行为,图画具有可版权性,使用者应为作者。
同时,域外各国、各地区对生成物的著作权法保护问题亦有争论,结果也并不相同。在激烈的讨论之中,有必要以更为冷静与谨慎的态度考察生成物所涉及的著作权法问题,本文试图从人工智能的本质及其基本逻辑出发,结合现行著作权法框架,探求生成物的本质属性及其可能的保护路径。
二、生成式人工智能的运行逻辑及生成物的生成逻辑分析
在界定生成物的性质之前,有必要对作为生成基础的生成式人工智能的发展情况、运行逻辑及生成物的生成逻辑进行分析,作为确定生成物地位的基础。
早在20世纪中期,人工智能就已经开始发展。2012年,AlexKrizhevsky等人提出了深度卷积神经网络(Deep Convolutional Neural Networks),引发了深度学习革命,推动人工智能技术质的跨越。在2016年与2017年,人工智能“AlphaGo”战胜了围棋世界冠军李世石与柯洁,标志着人工智能技术的进一步发展。
生成式人工智能也并非新兴事物,其早已在聊天对话、文本翻译等领域应用,直到以ChatGPT为代表的程序出现,其发展才进入到了新的阶段。2019年发布的GPT-2架构的神经网络规模数量为15亿个参数(parameters),而2020年发布的GPT-3架构的神经网络规模已经达到了1750亿个参数,GPT-4更是会达到万亿个参数的规模。虽相对于人脑神经元突触的百万亿规模还相差甚远,但不久,生成式人工智能的神经网络规模参数可能便会达到与人类神经元突触规模相当甚至超越的程度。由此,生成式人工智能已今非昔比,实现了质的飞跃。
人工智能生成物是生成式人工智能根据使用者输入的指令,基于人工智能设计开发者提前输入的信息数据,依照特定的规则程序训练而成的语言模型输出的结果。目前,生成式人工智能包括Ope-nAI公司的ChatGPT、百度公司的“文心一言”等,其已被广泛应用于例如文字、图像、视频等内容的生成之中。
生成式人工智能的运行逻辑,是解决人工智能生成物著作权法保护问题的逻辑起点。ChatGPT是目前生成式人工智能的最具有代表性的程序,对其运行逻辑进行分析具有典型意义。ChatGPT中的“GPT架构”是关键所在,全称为“Generative Pre-Trained Transformer”,即“生成式预训练Transformer模型”。简单来说,ChatGPT是一种基于Transformer架构经过预训练(Pre-training)与微调(Fine-tuning)后,可以依照使用者输入的指令作出回答,即可以与使用者聊天对话的人工智能模型。由此,对于人工智能生成物的生成而言,可以被分解为生成前与生成时两个阶段。
在人工智能生成物生成之前,主要是针对基于Transformer架构的人工智能模型的训练与迭代优化,即预训练(Pre-training)与微调(Fine-tuning)。原始的Transformer架构是一种利用编码器(Encoder)与解码器(Decoder)来处理序列数据(如自然语言文本)的深度学习模型,其采用了自注意力机制(Self-Attention)以更好地理解文本中的单词关系,并使用多头注意力机制(Multi-HeadAttention)来提高表达能力。亦即最原始的Transformer可以根据上下文内容来理解、预测并输出单词,用于处理语言理解任务,常见的应用包括语言翻译程序。GPT则只保留了Transformer中的解码器,以使其可以根据上文内容来理解、预测单词,在生成效率上高于原始的Transformer,主要用于语言生成任务。预训练包括数据收集、标记化(Tokenization)、Masked Language Model(MLM)目标训练、学习表示、迭代训练等内容。而微调则包括选择任务、数据准备、微调模型、超参数调整、评估和验证、迭代微调、部署和应用等内容。人工智能设计开发者主要负责设计整体架构、收集与预处理数据、使用选定的数据集和模型架构训练模型、评估与优化模型、部署与应用模型等工作。
人工智能生成物是由人工智能使用者输入指令触发人工智能来生成的,该阶段为人工智能生成物的生成时。使用者编辑内容并发送给人工智能,人工智能在接收到输入的文本内容后,会对文本内容进行编码处理以使模型能够理解与处理文本内容。之后,模型便会根据训练所学到的内容,以及使用者输入文本的上文,输出最为符合指令的内容返回给使用者。使用者主要负责指令参数的选择、输入、调整以及结果的选择等工作。
由此,ChatGPT是一个基于Transformer架构并通过预训练来自监督学习,使模型从巨量文本数据中学到如何理解上文(对话历史)、学习语言结构、语法和语义,通过微调来使模型更好地适应特定任务,并提高其在实际应用中的效果的聊天类生成式人工智能。简言之,人工智能本身可以按照程序设定的规则进行自我学习、运作、优化等工作。而设计开发者主要参与人工智能程序的编写、调适与部署,使用者主要参与触发人工智能程序的运行及对结果的选择。(见下图)
三、过程与结果视角下的人工智能生成物不符合著作权法规则
著作权法规定,作品是由某一主体创作的具有独创性且能以某种有形形式复制的,属于文学、艺术和科学领域内的智力成果,包括主体、独创性、可复制、领域及智力成果等要件。过程论认为,生成物不符合主体、独创性、智力成果要件,不具有可版权性。而结果论认为,生成物的可版权性问题的关键在于独创性判断,具有可版权性。
当某一主体创作了作品,且该作品符合著作权法要求的其他要件,则著作权法就应当保护该作品,亦即主体要件是著作权法保护作品的起点。结合著作权法第二条、第十一条第一款与《著作权法实施条例》第二条、第三条的规定来看,创作作品的主体应当是自然人。在菲某诉网某案中,法院就指出,人工智能生成物在内容、形态,甚至表达方式上接近自然人,但目前不宜突破民法的主体规定,自然人的创作仍应是认定作品的必要条件。因此,作为非自然人的人工智能并不能成为著作权法意义上的作者。
康德指出,在全部被造物中,人所愿欲的及其所能够支配的一切东西都只能是手段,只有人才是目的本身。亦即人工智能作为人的创造物,只能被视作为被人所支配的手段。在主客体统一认识论和人是目的的哲学命题下,作为人造物的人工智能只能是客体,居于从属地位,人与人工智能的地位不可颠倒。换言之,人工智能虽具有自主性与智能性,但这并不能改变其是人类用来生成人工智能生成物的工具属性。并且,人类创造人工智能的目的是为了利用该工具解放劳动力,而并非是为了替代人的地位及创造活动。若将确认其主体地位,必然会颠覆人存在的意义以及人的主体性。实际上,人类具有法律主体地位的重要原因之一,即在于其拥有自由意志,这种自由意志是人类具有权利能力的前提,但人工智能再过智能,也显然不具有作为法律主体前提的自由意志。
有学者认为,人工智能具有独立自主的行为能力,具有权利能力与行为能力,应承认其具有法律人格。然而,上述的ChatGPT的运行及其生成内容的逻辑表明,其自主行为的能力来源于人类设计开发者的数据输入、程序编写及使用者的指令介入,是一种人类智慧能力的间接延伸,本质上仍是基于设计开发者设定的规则及使用者的指令而进行的有限度的自主行为,是一种具有自动化、智慧化能力的工具,且这种智慧能力并不直接延及生成结果。因此,并不能因为有限的自主行为而承认其主体地位。例如,2017年,沙特赋予了人工智能机器人“Sophia”沙特国籍,“Sophia”是世界上第一个获得国籍的机器人。这似乎表明人工智能已经可以作为法律主体实施法律行为和参与法律关系活动。但实际上,这种赋予国籍的做法是一种形式上而非实质上的认可。ChatGPT虽不具有人类形态,但明显比“Sophia”更为智能,若是“Sophia”都能在实质上获得国籍身份,那么ChatGPT则更能获得。但从现实情况来看,世界各国及人类对ChatGPT仍持怀疑、谨慎的态度。可想而知,即使ChatGPT具有人类形态,也不会有国家愿意在实质上赋予其国籍。毕竟赋予人工智能以法律主体地位,必定是对将人工智能视为客体的现有法律制度的巨大挑战,且也会颠覆当前的社会公众的常识。简言之,承认作为客体的人工智能的主体地位,远离法理、逻辑和常识。
有学者就指出,无论人工智能发展到何种阶段,都只能作为人利用的客体和工具处理,而不能将其作为与人享有平等地位的法律主体。立法应契合当下的实际情况,而不能依靠对未来的幻想,否则可能会陷入为了接纳而接纳的逻辑陷阱中。实际上,在猕猴自拍案中,法院就认为猕猴及其他动物不具备版权法所要求的法律主体地位。2023年3月,美国版权局也再次明确,宪法与版权法中所使用的作者(author)一词排除了非人类(non-humans)的情况,亦即作者应为自然人。此外,在我国人工智能生成图画第一案中,法院也明确指出,著作权法要求的作者限于自然人、法人或非法人组织,而人工智能并不符合该规定,无法成为作者。这种做法是对人类主体性及作品必须由人类创作的理念的坚守,是值得肯定的。
有不少学者认为,在未来可以把人工智能当作新的民事主体对待,利用法律拟制技术将人工智能拟制为法律主体。从著作权法第十一条与第十八条来看,法人与非法人单位确实可以成为著作权法意义上的作者或著作权人。但就法人拟制的本质而言,法人属于人与财产基于特殊目的结合在一起的团体,将其拟制为法律主体是出于便利交易与责任限制的需要基于团体中自然人所具有的权利能力,法人拟制时,将自然人的能力直接延扩到法人团体中,因而法人具有权利能力。换言之,在拟制前后,法人本身并不具有意思能力,其能力始终直接源于团体中的自然人,自然人对法人的行为能力、权利能力均是一种直接的影响。并且,第十一条与第十八条在著作权法“著作权归属”这一节之中,在判断是否应当由法人或非法人作为作者或著作权人时,其逻辑前提仍在于有自然人创作了作品,再依照著作权归属规则将著作权移转给法人或非法人组织。
就人工智能而言,拟制的目的也不外乎利益需求,并且,人工智能虽经由自然人设计而成,但自然人所具有的自由意志实际上已经在映射在了相应的数据、程序与规则之中,人工智能在生成内容时,所进行的工作只是依照相关指令并遵循一定的规则,将相关内容组成符合人类语言、文字习惯的结果,并不能直接体现人工智能或其背后自然人的自由意志,因而其无法从人类参与者中直接获得自由意志。同时,设计开发人员的编写行为或只输入了一般性指令的使用者行为也无法认定是在“创作”生成物。例如,在猕猴自拍案中,代表猕猴进行诉讼的善待动物组织(PETA)就认为,版权法既然认可了法人或非法人组织具有法律主体地位,版权法也可以因此认定动物具有法律主体地位;但法院指出,版权法认可法人或非法人组织的法律主体地位的原因在于,这些团体是由人类组成并归属于人类所有的。换言之,在不存在自然人的前提下,动物抑或是人工智能实际上并不能具备或不能被拟制而拥有法律主体地位。因此,依照法人拟制的一般逻辑,人工智能难以被拟制为法律主体。
多迈尔曾提出,人的主体性观念正在丧失力量,现下是主体性的黄昏。人的主体性本质上是人的生命的自觉,是基于自我意识与自由意志而进行的实践、创造活动,进而实现人的目的与意义。若肯定人的主体性消解,而承认人工智能的主体性存在,则会出现人的存在与意义被逐步否定的困境。正如马克思所言,人应当承认自己是主体,按照人的样子来组织世界,否则可能会出现异化形式的社会联系。由此,人的主体性实际上是源自人的自由意志与情感情绪,而人工智能并不具备作为或拟制为主体的前提要求,从而,其本质上仍属于客体工具范畴。无论是直接将人工智能当作作者抑或是拟制为作者,无疑都会蚕食自然人作为主体的空间,并逐渐使得以人的样子所组织起来的世界被消解、异化,人工智能与由自然人构成、最终体现自然人意志的被拟制的法人并不相同,其无法成为创作主体或被拟制为法律主体。
因此,尽管现阶段的人工智能,如ChatGPT所基于的GPT-3以及即将到来的GPT-4,已经或即将具有类似于人的智慧——人工智能模型中的参数规模可以堪比人类大脑神经触点的规模,且开始具备类似于人类的思维能力。但毫无疑问的是,人工智能仍然与人类在思想情感与自由意志这个根源上具有区别,其无法成为或被拟制为著作权法所要求的创作主体,不符合著作权法的主体要件。
不论是过程论还是结果论,独创性要件的判断都是人工智能生成物可版权性判断的关键所在。由此,有必要分别从过程论与结果论的视角来分别讨论生成物的独创性问题。
我国著作权法及《著作权法实施条例》所规定的创作要件,是指直接产生文学、艺术和科学作品的智力活动,即独创性要求。从法律解释的角度而言,独创性分别有“独”与“创”两个方面。
“独”要求作品是独立创作、源于本人。不论创作行为是自主还是被动发生的,在创作行为发生之后,人类在创作过程中的行动应当是依其意志自主进行的,虽可能有他人的辅助工作,但不应由他人替代完成。由此,才有可能符合独创性要件中“独”的要求。ChatGPT产输出生成物的过程表明,在人类设计开发者、使用者等的参与之下,其才能依照指令触发生成行为,被触发之后的ChatGPT会依照指令并按照一定的规则、偏好进行输出工作。这种看似具有独立性的生成过程、源于人工智能数据模型的输出工作,实际上并不符合“独”的要求。原因在于,“独”表面上要求创作行为是独立自主进行的,但实际上仍然要求最终源自人类的自由意志或情感情绪而自主进行创作,在人工智能无法具备人类思想或情感的情况下,无法完全独立地完成生成工作。因此,人工智能的生成工作并不符合“独”的要求。
“创”要素要求作品具有一定的创造性,具备人类的个性特征,是人类的智力创作活动。“创”本身不仅有一定的高度要求,还要求作者有创造行为。其中,高度要求是指作品需要在一定程度上体现出创作者的智力活动及个性特征。有学者认为,人工智能生成物内涵了设计人员的人格要素。但一如前述的ChatGPT的设计开发人员主要参与数据的预处理、程序规则的编写调试以及维护等工作,人类的人格要素其实更多地是直接表现在数据选择、程序规则设计之上,人工智能生成物作为结果而言,并未受到直接的影响。换言之,创作是一种“直接产生”文学、艺术和科学作品的智力活动,但设计开发人员直接智力活动的结果,实际上指向的是人工智能程序,对于人工智能生成物并不构成直接的创作。同时,人的创造是基于自由意志所自然阐发的,而人工智能则受到了特定模型与程序的限制,难言有自由意志;即使认为模型与程序只是一种“环境”影响,人工智能也无法对指令作出类似于人类在意志上的反应而进行表达。因而,人工智能生成物在实质上并不符合“创”的高度要求。
创作行为则要求创作者的行为是在进行作品的创作,该行为是具有创造性的活动,对作品的产生具有直接的影响。索绪尔曾言,语言和文字是两种不同的符号系统,后者唯一的存在理由在于表现前者。这似乎表明人工智能生成物仅是一种语言的表现内容,在符合人类语法结构的情况下,其与人类作品并无不同。但是,虽人类的创造也受到了语言、语法结构的限制,可语言、语法结构也是人作为主体性存在所必须掌握的一种工具,且人类在这种有限的限制之前就有无限的自由意志,可以进行自由创造活动,只是为了获取利益、抒发情感等需要,而以语言、语法结构等作为表达的依托。这种进路可以被简化为“人类在有思想情感的情况下,为了获取利益或抒发情感等的需要,通过感官媒介这个手段来达到表达目的”。因此,以ChatGPT为例的生成式人工智能实际上是直接跳过了作为前提性存在的人的思想情感或意志,而直接通过MLM目标训练的方式模仿语言、语法结构等手段媒介来完成表达。同时,虽然Transformer架构使得ChatGPT拥有理解上文的能力,但这并不代表其具有与人一样的情绪感知或思想能力,其所具有的理解能力与模仿能力本质上仍是基于特定规则的机械模仿行为。人工智能所受到的更多的是一种本源上的限制——不存在人类智能及人类的自由意志,从而无法完成著作权法所要求的思想的表达。因此,人工智能所进行的只是一种脱离实质径直走向形式的本质机械而形似创造的行为,也不符合创作行为的要求。
2016年,日本发布的《知识产权推进计划》报告就否认了人工智能生成物的可版权性,原因在于,生成物不具有思想或情感的创造性表现。这种思想或情感的创造性表现只有人类才可能具备,而人工智能并不具备,不符合创造性的要求。同时,美国版权局审查委员会也在AI画作“A Recent En-trance to Paradise”案件中指出,由于该画作不具有人类的任何创造性贡献(creative contribution),且版权法所要求的作者应当为人类,因而该画作无法获得版权法保护。从思想表达二分法的角度而言,作品是思想的表达,亦即是人类思想情感的外在表现。这种表现是对混杂的人类的情感的澄清,而情感对于创作艺术作品的表现性动作是至关重要的。换言之,表现是把目的、感受或思想纳入一种感官媒介中,使表现自己、向他人表情达意的人可以从中再度体验到这种目的、感受或思想。海德格尔就指出,现身情态是此情此景的切身感受状态—情绪、有情绪,是人类存在原始样态,是有别于心理情绪的生存情感。在生存情感经过构形表现之后,其才有可能形成作品。人工智能再过智能,显然也无法具备与人类似的生存情感或现身情态,无法以其自我意识或思想情感参与到作品的创作之中,人工智能生成物只是一种人工智能借助人类所通用的感官媒介生成形似于人类作品的结果,仅是一种非思想的表达。
著作权法规定的作品获得保护的要求不仅是从形式上来说的,更是从实质出发的。虽然实践在判断某一作品是否具有可版权性时,多从该作品的形式、结果上来认定,但不可否认的是,这种判断仍然无法逸脱作品的定义及要件来确定其可版权性。著作权法第三条对作品进行了定义,并给出了相应的要件与示例性作品类型,内涵了在判断人工智能生成物是否具有可版权性时,可从其所表现的形式来直观判断是否符合作品的定义与示例性类型,这是简化的做法。但作品类型规定仅是对应受保护的作品的列举。更为重要的是,不论是定义还是示例性的作品类型规定,其都无法离开作为著作权法给予作品保护的前提性规定—作品的构成要件要求。亦即在直观判断无法解决作品可版权性问题时,仍应回归定义条款,比照其中的要件进行实质性判断,再综合其表现形式来确定是否具有可版权性或确定其所归属的作品类型。至于实践中多从客观形式来判断,则是忽略实质比对过程的做法,并不代表着对生成物的可版权性判断可以逸脱作品要件要求。因此,仅从结果来判断生成物是否具有可版权性的进路,有架空作品要件的嫌疑,使“符合作品要件——获得著作权法保护”的基本逻辑受到挑战。
不仅如此,人工智能本身是带有某种偏见的,并非所有的人工智能设计者在设计人工智能时都能秉持技术中立原则。因而,这种偏见所带来的结果使得人工智能生成物带有一定的欺骗性—人类许多时候难以通过本身的智慧辨别其中的欺骗性内容,仅仅依靠对独创性的判断无法解决可版权性问题。例如,若是以客观独创性标准承认了生成物的可版权性,那么类似于猕猴自拍案中的自拍照依据该标准是否能够构成作品?大猩猩也拥有大脑并有认知活动与行为,可以制造并利用工具、使用行为语言、了解符号含义以及拥有记忆力等,在亲缘关系上其也与人类相近。并且,早在20世纪50年代中期,一只名为刚果(Congo)的黑猩猩就已经能够出于自愿(ofhisownaccord)来使用绘画工具进行绘画,甚至在绘画中拿走工具,这只黑猩猩会请求拿走的人归还,在完成绘画后,他会拒绝继续绘画。因而,从客观独创性的角度而言,这类与人近似、拥有智慧与技能的灵长类生物“创作的作品”在外观上似乎更符合著作权法的要求而应获得保护。但显然,人类暂时无法接受利用客观独创性标准来认定动物“创作物”成为著作权法意义上的作品。同理,也不应认可利用客观独创性标准来判断作为非生物的生成式人工智能的生成物的可版权性。
现代社会的人们对多样性的需求越来越大,伴随而来的是对原创性(独创性)要求的提升。换言之,若是选择将人工智能生成物的可版权性问题简化为独创性问题,表面上能够满足人们的需求,但却会导致许多低原创性的生成物进入到作品领域,且会削弱、虚化其他要件,导致作品的泛滥,对一般的人类作品产生负面影响、将过多的公有领域的信息纳入私有领域,会产生一种反噬的效果,实际上剥夺了人对优质、高原创性作品的追求。因而,仅从结果角度来判断生成物可版权性问题的分析进路,是值得警惕的。因为,若是采纳了客观独创性标准,则著作权法可能会从人类创作的激励者成为资本逐利的工具。
再者,虽然多迈尔曾提出主体性黄昏的观点,似乎印证了著作权法主体要件可以被忽略。但是,其也认为全盘否定主体性是糟糕的。康德就认为,当人类努力使自己上升到大自然所赋予人们的萌芽在自己身上充分地发展出来的状态时,他们的使命就可以在大地上得到实现。亦即人类总是在进步的过程中,尽管主体性存在问题陷入了一定的困境,但这并不代表着主体性的消解,而只能说明主体性正在随着人类的发展而发展,使得主体性愈发迈向成熟。著作权法上的主体要件,也会随着哲学意义上主体性的成熟而更加坚定,而非被逐渐消解。有学者提出,身份原则或者说主体性要求扮演着“守门人(gatekeeper)”的角色,决定了权利归属及权利的主体。换言之,忽视了著作权法保护作品的前提性的主体要件而径直向客观独创性逃逸的做法,会大大降低著作权法的门槛,使得权利被无限制地赋予本不应享有权利的“主体”或客体,是不可取的。
最后,虽从结果判断人工智能生成物的可版权性可能符合立法目的,我国著作权法第一条规定了立法的直接及最终目的—保护著作权与公共利益、促进作品创作与传播、促进社会主义文化和科学事业的发展与繁荣。但至于是否以该法保护生成物,还是应从作品的定义出发。原因在于,著作权法保护作品的基本逻辑在于,某一作品符合该法的要件要求,再赋予或明确作者的著作权受到保护,以实现立法目的。而从保护投资者利益、促进产业发展、鼓励创作等角度出发,要求生成物获得著作权法保护,是一种“本末倒置”的近路,即该法是以保护作品为前提(手段)来达到立法目的的实现(目的),并非以立法目的为由来保护作品或非作品信息。后面这种看似正确的逻辑,可能会导致立法目的条款的虚化与泛滥,亦即以立法目的为出发点将公共领域的信息纳入著作权法的框架中进行规制。因此,从结果意义上来判断人工智能生成物的可版权性的做法,实际上是虚化了著作权法的立法目的与精神,并不可取。
由此,仅从结果来判断人工智能生成物是否具有可版权性过于片面,虚化了著作权法保护作品的前提,尤其是当该种进路独独重视独创性要件而架空甚至消解作为逻辑起点的主体要件及其他要件时。
有学者提出,著作权法保护的是作为智力成果的作品,因而人工智能生成物有可版权性的可能。著作权法规定,作品的本质是一种“智力成果”,亦即从法律条文的表述来看,这种观点并无不当。但现代著作权法立法的原因即在于保护与鼓励人的创作。例如,“The Statute of Anne”指出,该法的目的在于鼓励有学问的人(learned men)创作和撰写有用的书籍,“learned men”的表述表明,创作作品或者说创作智力成果的主体应当是人类。结合现行著作权法的作品立法目的、定义等条款也可以发现,作品的创作者应当是自然人,保护作品的原因与目的也是因为人类创作了作品。换言之,著作权法所保护的是人类的智力成果,智力成果要件与人类这个主体要件是密不可分的。不仅如此,从前述对独创性要件的分析也可以发现,“独创”是基于自由意志与思想情感的一种创造性活动,也暗含了只有拥有自由意志与思想情感的人类才能作出该活动,并进而创造出智力成果。因此,一般性的人工智能生成物并非智力成果,无法构成作品,无法受到著作权法保护。
综上,人工智能在本源上不具有自由意志或思想情感,且只受到了设计人员人格的间接的影响,故而无法满足主体性或独创性要件的要求。同时,人工智能生成物也因不具备作为前提性存在的人类思想情感,而无法满足智力成果要件。
四、过程与结果论争的本质是作者与读者中心主义的对峙与抉择
过程论聚焦人工智能的生成过程,而结果论则围绕人工智能生成的结果,来判断人工智能生成物的可版权性。进一步剖析发现,过程论关注的是作者的创作及与作者有关的因素,与作者中心主义有关。而结果论关注的是作品作为单纯文本是否具有可版权性,是读者中心主义的典型分析方法。
作者中心主义旨在将作者置于神圣的地位。因而,在判断作品可版权性时,作者及其个性特征被置于中心地位,即作者是作品的创作者,作品是其人格延续与劳动创造的结果,作品是作者的“孩子”。在此理路要求下,与作者有关的主体身份、创作意图及行为等过程性因素是独创性判断的关键。简言之,作者中心主义主要考察“作者为什么创作”以及“作者如何创作”。
而读者中心主义则肇始于西方结构主义哲学,也被称为作品中心主义,主张将作者的个性、人格从作品中剥离出去,作品的意义应由读者来赋予。原因在于,语言是一种符号系统、价值系统,而文字唯一的存在理由在于表现语言。亦即在判断作品独创性时,应将其视作是一种用于表达语言的文本,不应受到作者的主体身份、创作意图及行为等过程性因素的影响,而应以读者自己的情绪情感及经验来直面并理解被作品表达出的语言的含义。因此,读者中心主义可以被理解为将作品文本化与去语境化,读者应当探寻语言所要阐发的一种与作者无关的“事物”,亦即读者从自身的视角来发现或赋予作品意义。
由此,过程论是从作者的身份、创作意图及行为出发,而结果论则从作品作为文本的客观形式出发对人工智能生成物的法律属性进行界定,这两种进路背后隐含了以作者为中心与以读者为中心的理据。
以作者为中心代表性立法体例为作者权体系,而以读者为中心的代表性立法体例则是版权体系。有学者指出,在市场统一的境遇下,作者权体系有所消解,著作权法趋向了版权体系。在这样的导向下,著作权法愈发以读者为中心,忽视了作者的地位,从而颇多学者在论述人工智能生成物的可版权性时采用结果论,无意识地将生成物的可版权性问题简化为独创性判断,消解了构成作品本应具备的其他要件。过程论与结果论之争的本质在于作者中心主义与读者中心主义的对峙、融合与抉择,在两种主义的对峙之下,生成物的可版权性问题难有定论。因此,有必要先理清两大主义所据以设立的理论基础,再解决生成物可版权性问题。
作者中心主义主要受自然法理论的影响,该理论要求,财产权利产生的原因在于个人将其劳动附加在人类所自然共有的事物上,且无浪费行为,在公有领域留下相同且足够好的东西。因此,自然法理论认为著作权产生于作者的创作行为,其最终目的在于保护作者私权,公益只是限制私权的原因。
读者中心主义则主要受到功利主义理论的影响,该理论也称激励理论,主张给予劳动者报酬的目的在于,激励劳动者创造更多产品造福社会上的多数人。亦即功利主义理论认为著作权法的作用在于创设权利保护作者,以激励作者创作,促使作者为社会提供更多作品而促进公益的最大化实现。
因此,人工智能生成物是否可以获得著作权法的保护,实际上关涉自然法理论与功利主义理论的选择。当前,多数学者主张从结果角度来判断生成物的可版权性。但两种主义所对应的国家、地区的多数观点都主张生成物无法获得著作权法保护。即使是坚持读者中心主义的美国,也认为主体要件无法被突破,难以仅通过客观独创性的判断来确认生成物的可版权性。原因在于,两种理论具有耦合性,单一角度下的生成物可版权性判断进路都存在难以自洽之处。
不论何种理论,著作权法的立法目的无外乎保护作者私权与社会公共利益,并在其中寻找平衡。但是两种理论出发点的不同,造成了在无法平衡作者私益与社会公益时,法律可能会倾向某一方的利益而使得保护发生片面化,尤其是利用单一理论构建的著作权法制度。如,以作者为出发点的自然法理论往往会重视作者私权,使得私权被赋予高于其他权益的优先权地位,导致著作权独占主义的抬头,而忽视了社会公益。又如,以读者为出发点的原始功利主义所带有的公益倾向,使得现代功利主义为避免公益的过度保护而也过分强调私权保护,导致著作权扩张运动盛行,缺乏对公益与私益的平衡。就人工智能生成物而言,在坚持过程论时,往往会忽视了社会公众对文化的繁荣需求;在坚持结果论时,往往会损害到一般人类作者的私益。
其实,著作权是建立在自然权利之上的法定权利。功利主义理论与自然法理论的本质是相同的,均谋求私益与社会公益间的平衡,两个理论具有耦合性。我国著作权法的立法目的,就暗含了两种理论的耦合。其中,立法的直接目的在于保护作品作者的著作权,带有作者中心主义的烙印。同时,立法的最终目的则在于传播作品、促进文化繁荣,意欲维护公益,带有读者中心主义的印记。
但是,按照法律的一般逻辑,实现立法目的需通过一定的手段途径,即著作权法通过保护符合作品要件的作品,来实现立法的目的。因此,在人工智能生成物的可版权性判断之中,过程论与结果论都有片面性,表面上合乎立法目的,但实际上可能会出现利益失衡问题,使得私益或公益被不当放大或限缩,导致立法目的难以被有效实现。因此,亟须依照“通过手段实现目的”的基本逻辑,找到一条既合乎作品要件又能实现立法目的进路来解决生成物的可版权性问题。
人工智能生成物若欲获得著作权法的保护,首先仍需符合该法关于作品要件的要求以获得保护的前提性条件,在此基础上实现相应的立法目的。纵观各国家、地区的观点来看,日本对人工智能生成物的态度曾发生过较大转变,其中所蕴含的理念值得注意。日本在2016年的《知识产权推进计划》报告中指出,人工智能生成物不具有思想或情感的创造性表现,因而不具有可版权性。而2017年日本新型信息财产检讨委员会的一份报告指出,有创作意图的人工智能使用者,对于输出人工智能生成物具有创造性贡献的,则该人工智能生成物可以被认为表现了使用者的思想或情感,从而可以受到著作权法保护,该人工智能使用者是该生成物的作者。
马克思主义法学认为,法律本质上是一种行为规范,所针对的是人类及其行为。而日本的转变,实际上正是考虑到了作者中心主义与读者中心主义在对峙之中亦有耦合,亦即最终都是为了实现人类的利益,将人类作为目的,重新将人类作为考察对象。换言之,日本的做法本质上是从对人工智能这个客体的“行为”的考察,重新转向考察人工智能的人类参与者的意图与行为,将人工智能生成物的可版权性判断从人工智能的“创作”之中与“创作”之后提前至“创作”之前,以使用者的参与情况作为标准,对生成物进行分类定性保护。对于分类规制,《布莱切利宣言》也指出,各国可以根据国情和自身的法律体系框架对人工智能所涉的风险进行分类和归类治理。可见,日本的做法符合国际上人工智能的治理趋势,对我国人工智能生成物的著作权法保护问题极具启发意义。
五、人类参与视角下人工智能生成物的著作权法分类保护路径
人工智能生成物的保护问题涉及最新的智能技术,应当秉持谨慎、理性的态度解决新技术带来的法律问题,在没有充分理据支撑的情况下,不宜轻易突破现有的著作权法框架。从现实需求出发,基于人类参与情况对生成物进行分类保护,或许是在现行著作权法框架下切实可行的方案。
人工智能生成物不符合作品要件要求而无法受著作权法保护。原因在于,人工智能程序不具备人类的思想情感,且其输出行为不属于创造行为,即不符合主体、独创性与智力成果等要件的要求。因此,将人工智能生成物纳入著作权法保护的前提,就是要解决主体、独创性等要件符合性的问题。
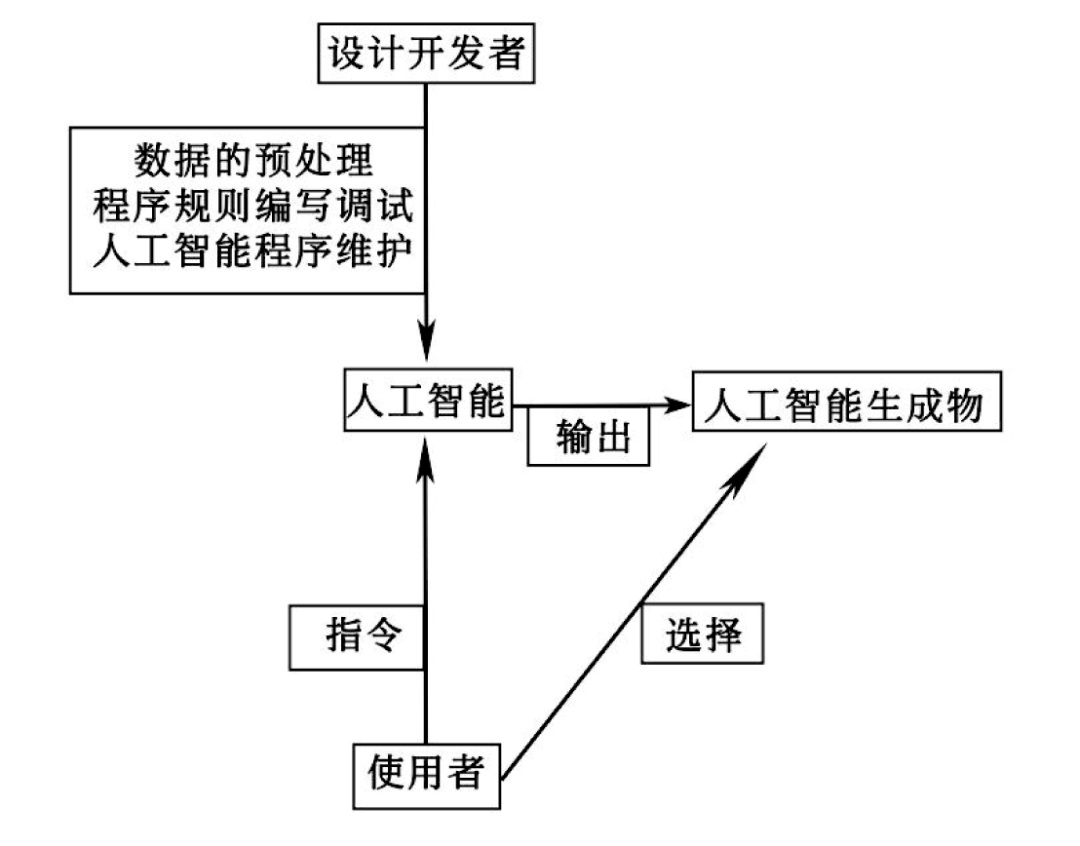
以ChatGPT为例,在ChatGPT生成内容之前,需要人工智能设计开发者进行输入数据、编写程序等工作,但这些工作本质上是在直接创造ChatGPT程序,对人工智能生成物并无直接影响,无法认定生成物是由设计开发者创造。而在ChatGPT生成内容时,需要人工智能使用者输入指令,再由Chat-GPT依照设定的程序规则及数据模型库,来输出符合人类语言、语法结构习惯的结果,即使用者对ChatGPT生成内容具有关键性作用。因而,使用者的参与情况是判断生成物是否具备可版权性的前提与关键所在。
在我国人工智能生成图画第一案中,法院就指出,人工智能使用者通过输入提示词、调整参数设置来利用人工智能程序生成图画,并在获得第一张图片后不断修正参数、增加提示词,这种调整修正以及选择的过程体现了审美选择和个性化判断,具有独创性。同时,使用者的创作意图及行为直接表现在图画中。并且,使用者设计人物的呈现方式、选择提示词、安排提示词的顺序、设置参数、选定图片等行为属于智力投入行为,可以认定为是其智力成果。因此,涉案图画是使用者利用人工智能程序创作的作品,由使用者享有著作权。
由此,在使用者具备创作意图,输入的指令具有创造性贡献,且该人工智能生成物也符合作品的可复制、领域等其他要件要求时,则其具备可版权性,使用者应被视为作者。原因在于,此情形下的生成物附加了使用者的创作意图,使得使用者的思想情感能够作为前提性存在表现在生成物之中。同时,使用者的创造性指令也使得生成物中能够表现出人类的创造性贡献。不仅如此,使用者在对指令的不断选择、调整,实际上也能体现出使用者创作意图与行为对人工智能的生成行为的直接影响。在以读者为中心的情形下,这种直接影响使得读者能够依照自己的意志赋予该生成物以意义。而在以作者为中心的情形下,这种直接影响实际上已经足以使得作者能够将其意志体现在作品之中。总言之,使用者的创作意图、创造性贡献及智力投入使得生成物缺乏思想情感、独创贡献及行为、智力成果等的因素得到弥补,因而,此时的生成物具备符合主体、独创性与智力成果等要件的可能性。(见下图)
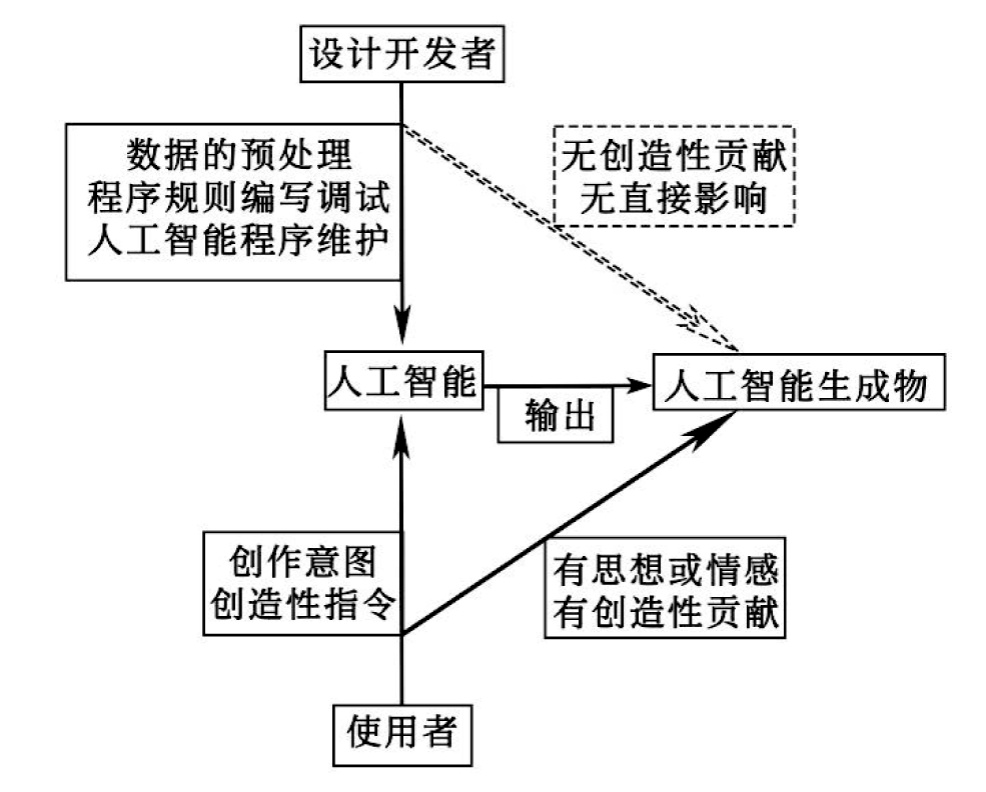
实际上,在上述人工智能生成图画第一案判决作出后,就有不少人认为这种结果会引发人工智能生成物的泛滥、使得人类及其作品价值的退化,甚至导致著作权法的地位受到挑战。虽然这是社会公众的探讨,但却也可以表明生成物受保护而引发的著作权法危机及其所带来的结果是目前公众的朴素法感情难以接受的。换言之,生成物存在生成方便、高同质性与低原创性的情况,使得将生成物纳入著作权法保护会导致作品与权利泛滥的后果,并进而损害人类作者的利益,因而无法被公众所接纳。在此种情境下,有必要明确使用者输入的创造性贡献应是直接针对生成结果的,并且,这种创造性贡献不能低于人类创作作品时所具有的“源自本人、表现其个性”的标准。在判断其创造性贡献时,除要考察使用者的创作意图及输入指令的内容时,还应结合使用者的参数与指令的调整与优化、结果的选择、结果是否符合创作意图或思想情感以及关键词、参与行为的质与量是否足够充分等内容来判断,以防止低质量的生成物被纳入著作权法中保护。
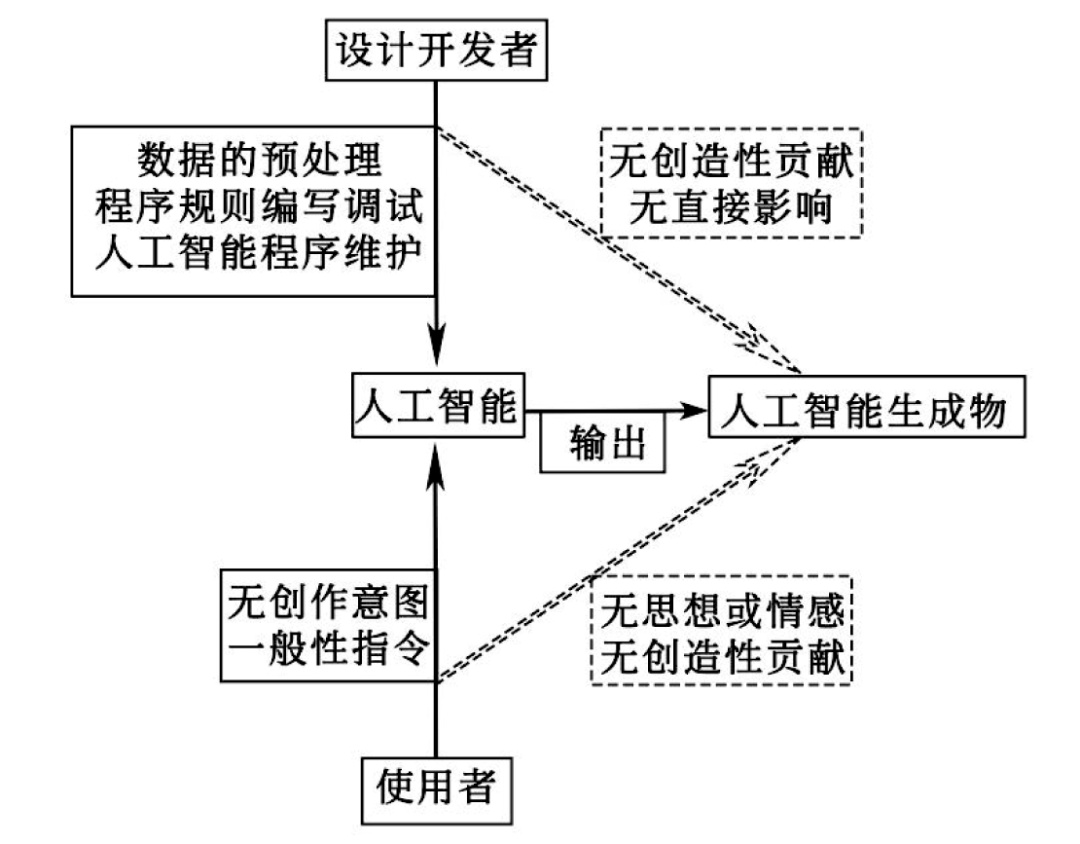
对于人工智能使用者未输入创造性指令或者只输入一般性、无创造性的指令的情况,即人类参与者无创作意图且对生成结果不具有创造性贡献时,人工智能也会基于该指令输出结果。在菲某诉网某案中,法院就指出,人使用者仅提交了关键词进行搜索,应用可视化功能自动生成分析报告,该报告并未传递使用者思想、感情的独创性表达,故,该报告不宜认定为使用者创作完成。换言之,这种仅依靠输入个别关键词的做法,无法表现使用者的创作意图,也无法表明使用者对人工智能生成物有创造性贡献。因而,这类生成物不符合主体、独创性以及智力成果等要件,无法具备可版权性。(见下图)
在不具有可版权性的情况下,人工智能生成物应当被作为非作品信息而进入到公共领域之中。对此,有不少学者持有类似于人工智能设计开发者失去了激励,难以推动人工智能产业的发展的观点,即“保护投资论”。但需要指出的是,此处混淆了人工智能程序与人工智能生成物,对于设计开发者而言,其激励实际上已经从人工智能模型中数据所附有的权益以及人工智能程序的应用之中获得,而生成物则是使用者输入指令后由人工智能输出的产物,并不是设计开发者直接控制获得的,若是让设计开发者享有人工智能程序的著作权的同时,再享有并非由其直接控制获得的生成物的利益,则会有过度激励(over-reward)之嫌。
正如有学者所指出的,没有人类作者参与的人工智能生成物应当进入公共领域,因为此时没有人类创造了作品,著作权法也就无需对此进行激励。同时,人工智能产业具有显著的先发优势利益,可以因其先进的技术获得竞争优势及利益。现阶段的生成式人工智能程序本身可以获得版权法的激励,并且,人工智能程序背后的公司一般还会对人工智能使用者收费,可以做到有所收益。例如,OpenAI公司就会依照不同的语言模型(GPT-3.5 Turbo、GPT-4、Assistants API等)并依据单词量(tokens)对使用者进行收费。可见,具有可版权性的人工智能程序本身及利用该程序向使用者收费实际上已经能够让人工智能设计开发者获益,虽然目前可能无法做到完全的“投有所报”,但这并不代表着在成熟的生成式人工智能铺开应用后,相关设计开发者不会收到足够的报酬,否则也不会有这么多国家、地区、公司全面推进AI产业的发展。原因在于,人工智能过于强大,以至于该产业是一场国际竞赛,无论是否有版权法的激励,人工智能研究都会持续繁荣。例如,作为开发公司的OpenAI,在ChatGPT的生成物未获版权法保护的情况下,仍旧扩大投资并奋力训练GPT-4等更为先进的人工智能。而首届全球人工智能安全峰会的召开,其实也可以印证AI产业关涉国际竞赛,各国会不遗余力地发展人工智能产业,从而影响到全球AI格局甚至是全球社会经济文化格局,因而才有必要达成共识,将AI产业置于安全的框架内发展。可见,生成物是否获得版权法的激励,并非人工智能产业发展的必要前提和条件。
不仅如此,认可人工智能生成物的可版权性并由设计开发者享有其著作权,则其将必然承担相应的义务。从利益平衡的角度而言,在设计开发者对生成物没有直接控制力的情况下赋予其权利与义务,显然会导致利益失衡的后果,并极有可能引发设计开发者的反对。类似的情况正如1998年美国政府试图让网络服务提供者对用户的侵犯版权的行为承担责任,而遭到网络服务提供者的反对一样;在网络服务提供者对用户的侵权行为并没有真正的控制权(had no real control)的情况下,贸然让其承担侵权责任是不可行的。换言之,设计开发者实际上仅对人工智能程序本身具有直接控制权,但对生成物的输出仅有间接的影响且对生成物本身并没有创造性贡献,这种情况下让其承担无实际控制权的行为所带来的权利或义务显然是不合理的。与此同时,使用者对于输出行为有直接控制权,但由于生成物的可版权性问题是针对生成物本身而并非针对输出行为,因此,在使用者对生成物不具有创造性贡献且并不符合作品要件要求的情况下,生成物并不具有可版权性,使用者也无法享有相应的权利。
因此,无使用者创造性贡献的人工智能生成物进入公共领域有充分的理由,不会对投资或设计开发者抑或是使用者造成损害,反而会使得公共领域有更多的数据信息供公众使用,推动人类作者利用这些数据信息创作更多作品,这也符合著作权法传播作品、促进文化的繁荣、维护公共利益的最终目的。
此外,对于人工智能生成物中是否具有使用者的创造性贡献的判断,可以要求人工智能设计开发者对使用者的使用情况进行提取、记录。同时,由使用者通过提供其所输入的指令内容、生成结果、使用信息等来证明其是否输入了具有创造性的指令,以避免两种生成物混杂的情况。例如,使用者在使用ChatGPT时,其历史对话数据、生成的文本等信息会被保留30天。这种数据保留的做法,实际上为甄别生成物的类别提供了可能性。又如,我国人工智能生成图画第一案中,使用者就根据自己设定的提示词和参数还原了该图画的生成过程,使得法院最终认定该图画是由使用者利用人工智能程序生成的。可见,将证明生成物的类别的责任赋予使用者是可行的。
人工智能生成物在外观上与人类作品相似,一般人都无法识别其是否为生成物,因而也存在冒用自然人身份的情况。《布莱切利宣言》指出,人工智能设计开发者应当通过安全测试系统、评估和其他适当的措施来确保人工智能的安全发展。2023年10月30日,美国政府发布的关于生成式人工智能的行政监管命令,要求生成式人工智能应当在输出时,嵌入难以删除的信息水印(watermarking),用于验证输出的真实性、出处、修改或传播的身份或特征。因此,在输出生成物时,人工智能设计开发者应负有强制标识义务,对生成物附加信息水印或其他标记以作识别的目的。而人工智能使用者对生成物的输出也有直接控制权,因此,其也负有在利用该生成物时,附加标识以表明该生成物由人工智能程序生成的义务。这种做法可以在一定程度上区分生成物与人类作品,避免两者的混同。
综上,在过程论与结果论难以解决人工智能生成物著作权法保护问题时,应当基于现实需要,在作者中心主义与读者中心主义之间选择了考察人类行为,以人类使用者的参与情况作为基准,将生成物进行分类定性保护。同时,生成物应当附有由人工智能程序生成的强制性标识,以与人类作品相区分。
结语
人工智能生成物的著作权法保护问题在近年来讨论颇多,现有的过程论与结果论之争本质是作者中心主义与读者中心主义的对峙,现时世界各国、各地区均不赞成以著作权法保护生成物。出于现实需要,应从考察人工智能生成行为转向考察人类参与行为,基于人类使用者的贡献度对生成物进行分类保护,并附加由人工智能程序生成的标识。这种做法不仅符合著作权法所要求的作品保护要件,也符合著作权法的立法目的,更符合现实需要。
往期精彩回顾
商建刚 张银超|循规而行·数据致远——2024数据要素流通论坛会议综述
陈泽坤|论运输合同性质的识别标准——以门到门航空货运服务为例的分析
邹毓家|大湾区涉外商事纠纷司法规则的衔接范式与举措完善——基于广东三大自贸区的法治研究
目录|《法治文化》集刊2024年第1卷
包于宏等|防范化解重大风险视域下优化自贸区营商环境的法治路径——基于舟山片区的探索实践
罗晓琴|论长三角生态绿色一体化发展示范区执行委员会的法律地位
上海市法学会官网
http://www.sls.org.cn